
Neste artigo você encontrará:
Bem-vindo a mais um artigo em que vamos explorar as ferramentas de tecnologia que estão transformando a maneira como trabalhamos com dados em Data Science. Hoje, vamos falar sobre uma ferramenta chamada Docker, extremamente útil não apenas para desenvolvedores de software, mas também para cientistas de dados.
GUIA COMPLETO
SOBRE DATA SCIENCE

Docker, o que é?
O Docker é uma plataforma aberta que foi projetada para facilitar o desenvolvimento, o envio e a execução de aplicativos. Ele permite que você separe suas aplicações em diferentes “containers”, que possuem tudo o que é necessário para a aplicação funcionar corretamente. Isso inclui o sistema operacional, as bibliotecas, as variáveis de ambiente e os arquivos de código-fonte.
O Docker usa a tecnologia de virtualização a nível de sistema operacional, conhecida como “containerização”. Diferente da virtualização tradicional que cria máquinas virtuais completas, a containerização permite executar várias aplicações isoladas no mesmo host, compartilhando o mesmo kernel do sistema operacional, mas mantendo o isolamento entre elas. Isso torna os containers muito mais leves e rápidos do que as máquinas virtuais tradicionais.
Por que Docker é útil para a Ciência de Dados?
A Ciência de Dados requer uma combinação complexa de habilidades, envolvendo codificação, análise estatística e aprendizado de máquina. Nesse campo, costumamos usar uma variedade de ferramentas e bibliotecas de software, cada uma com suas próprias dependências. Gerenciar essas dependências pode ser um grande desafio.
E é aqui que o Docker entra em cena. Com o Docker, você pode criar um container que possui todas as bibliotecas e ferramentas necessárias, garantindo que tudo funcionará corretamente, independente do ambiente em que você está trabalhando.
Aqui estão algumas razões pelas quais o Docker é extremamente útil na ciência de dados:
- Reprodutibilidade: Ao criar um Dockerfile (um script que define o ambiente do container), você garante que sua análise de dados ou modelo de aprendizado de máquina possa ser executado de forma idêntica, independente de onde está sendo executado.
- Isolamento: Cada container funciona como um ambiente isolado. Isso significa que você pode ter diferentes projetos, cada um com suas próprias dependências, rodando no mesmo computador sem que eles interfiram uns nos outros.
- Portabilidade: Uma vez que o container esteja construído, ele pode ser facilmente distribuído e executado em qualquer lugar que suporte Docker, seja seu próprio laptop, um servidor na nuvem ou até mesmo uma plataforma de produção em larga escala.
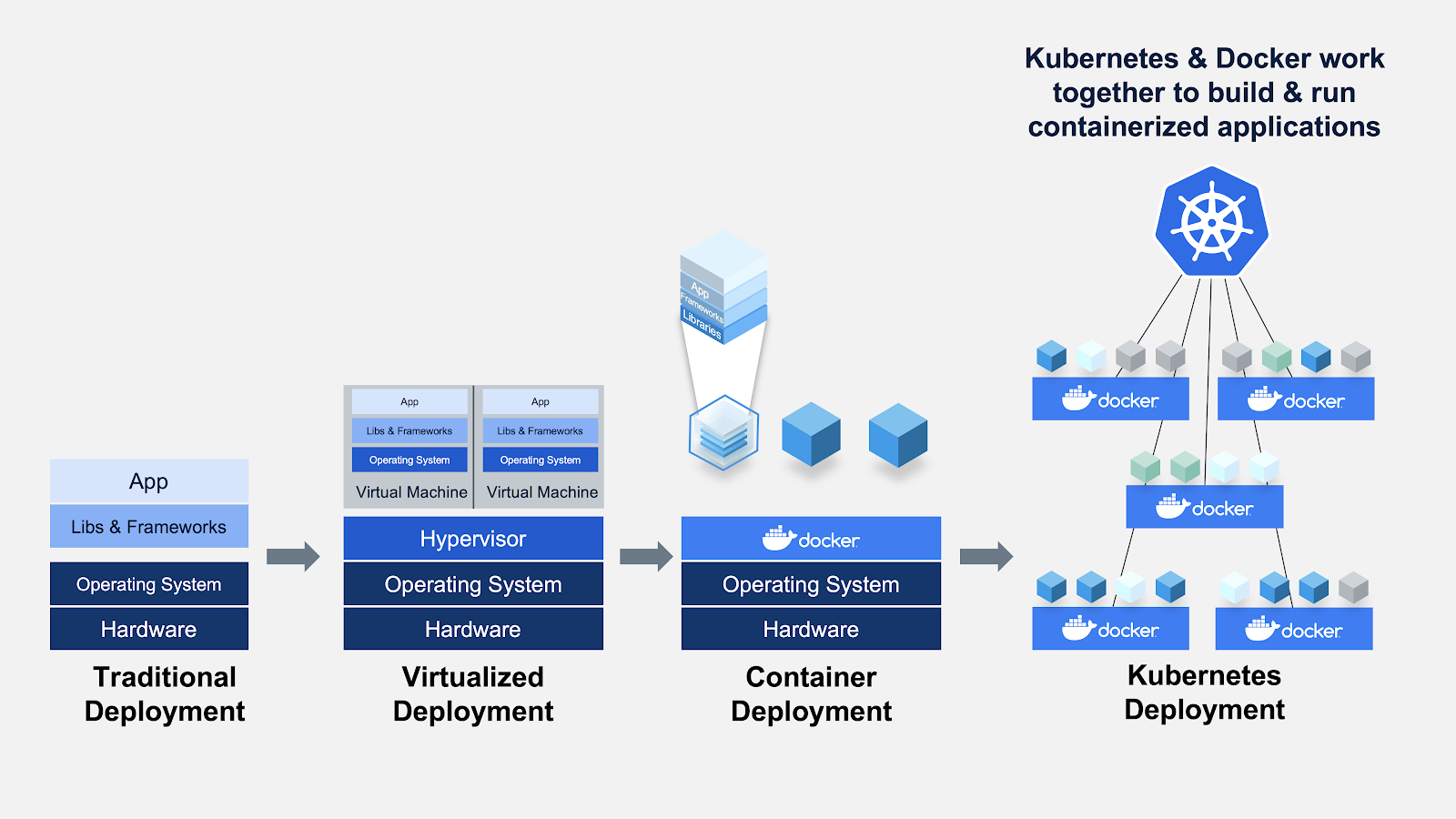
Como usar Docker para Ciência de Dados?
Agora que entendemos Docker, o que é e por que ele é útil para ciência de dados, vamos dar uma olhada em como podemos usá-lo.
- Instalação do Docker
O primeiro passo é instalar o Docker em sua máquina. As instruções de instalação variam dependendo do sistema operacional que você está usando (Windows, MacOS ou Linux), mas você pode encontrar tutoriais detalhados na documentação oficial do Docker.
- Criando um Dockerfile
Uma vez que o Docker esteja instalado, você pode criar um Dockerfile. Este é um script que define o ambiente do seu container. Aqui está um exemplo simples de um Dockerfile que instala Python e algumas bibliotecas de ciência de dados:
# Usar uma imagem base do Python
FROM python:3.8
# Definir o diretório de trabalho no container
WORKDIR /app
# Copiar o arquivo de requisitos para o container
COPY requirements.txt .
# Instalar as dependências
RUN pip install –no-cache-dir -r requirements.txt
# Copiar o restante do código para o container
COPY . .
GUIA COMPLETO
SOBRE DATA SCIENCE
- Construindo e executando o container
Uma vez que o Dockerfile esteja pronto, você pode construir seu container com o comando docker build. Em seguida, você pode executar seu container com o comando docker run.
- Compartilhando seu container
Se você deseja compartilhar seu trabalho com outros, você pode publicar seu container no Docker Hub.
Docker é uma ferramenta poderosa que pode simplificar significativamente o trabalho de um cientista de dados. Se você ainda não está usando Docker em seu fluxo de trabalho, esperamos que este artigo tenha lhe dado uma boa ideia de por que você deveria começar a usá-lo.
Se você está pronto para aprofundar suas habilidades e conhecimentos em ciência de dados, o Instituto Infnet oferece um Bootcamp de Ciência de Dados, projetado para equipá-lo com o conhecimento e as habilidades necessárias para se tornar um profissional de alto nível nesta área.
Então, por que esperar? Saiba mais sobre o Bootcamp de Data Science do Infnet.